Internet Download Manager Grabber-向导
步骤1.设置开始页面
在向导的第一步,您应指定起始页面。默认情况下,假定为http协议; 需要明确指定其他协议,如https。起始页面还设置当前站点。例如,如果您指定了http://www.tonec.com/support/index.html,则当前站点将是www.tonec.com,并且所有支持的协议(如ftp,https,http)都应用于此站点名称。

如果站点需要授权,您还应在此步骤中设置登录名和密码。有些网站只允许在特定页面上进行身份验证后进行浏览/下载。在这种情况下,您应按“高级>>”按钮,选中“手动输入登录名和密码”框,并指定登录该站点的页面。此外,如果站点具有注销按钮,则应在此处指定Grabber不应打开的注销页面。如果您设置了登录页面,Grabber将在第四步之后打开浏览器窗口,让您在继续浏览和下载之前手动登录该站点。
如果您计划保存抓取器项目以供以后使用,则需要选择一个唯一的项目名称,并在对话框顶部的“Grabber Project Name”字段中输入该名称。项目名称显示在主IDM对话框的类别树中已保存项目的列表中。
如果您需要从网站下载所有图片,视频或音频文件,或下载完整的网站,您可以在项目模板列表框中选择适当的模板。项目模板可以让您轻松快速地启动项目,因为所有必需的设置都是自动完成的。
但是没有必要选择项目模板。项目模板在项目中进行预定义设置,以用于后续的抓取器向导步骤。如果您使用相同的Grabber设置从网站下载文件,您可以在此步骤中选择“自定义”模板,在下一阶段进行必要的设置,然后选择“项目 – >保存当前设置”将设置另存为模板作为模板“菜单项。
步骤2.选择将文件保存到的位置。
在第二步,您需要选择保存所有下载文件的位置。
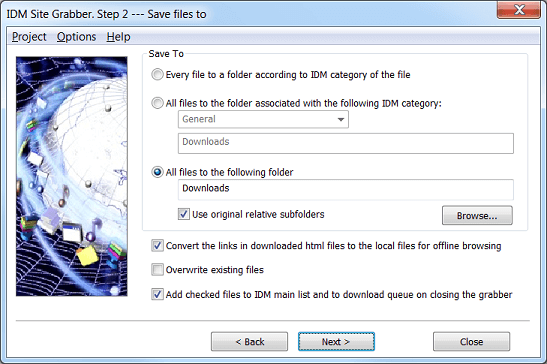
您可以根据文件的类别将每个文件保存到文件夹。例如,如果您定义了列出zip arj和rar文件类型的“压缩文件”类别,并且它有一个关联的文件夹,例如c:\ my documents \ myname \ downloads \ compressed,那么所有下载的zip,arj和rar文件将保存到c:\ my documents \ myname \ downloads \ compressed文件夹。
您还可以将所有下载的文件保存到与所选类别关联的文件夹中。您需要选择相应的单选按钮,然后选择一个类别。抓取器将找到并显示该类别下方的目录。
如果要创建在网站上创建的所有文件夹,可以选择保存所有下载文件的目录,并选中“使用原始相对子文件夹”框。
如果您要下载完整的网站或网站的一部分,则可以选中此框以将链接转换为本地以进行脱机浏览。在第一步中选择不需要保存任何html页面的模板时,此复选框将被禁用,例如“网站中的所有图像”模板。下载所有选定文件后或停止抓取器后,抓取器会将下载文件的链接转换为每个下载网页的本地相关文件。此外,抓取器会将未下载的文件(远程文件)的所有链接转换为绝对互联网链接。
如果未选中“覆盖现有文件”框并且已存在具有相同名称的文件,则抓取器将在文件名中添加下划线和数字,例如index_2.html。
没有必要选中“将已检查的文件添加到IDM”框,主Grabber窗口工具栏上有一个具有相同功能的按钮,可将所有选定的文件添加到Internet Download Manager的主下载列表中。如果选中此复选框,则抓取器会在关闭抓取器时自动将所选文件添加到IDM。
步骤3.设置文件过滤器。
在此步骤中,您应指定要探索的网页以搜索所需文件。请注意,您仅为已探索的网页设置条件。您可以在下一步中为下载的文件设置文件类型,位置和其他过滤器。

您在第一步中指定的起始页面设置要探索的当前站点。例如,如果您指定了http://www.tonec.com/support/index.html,则当前站点将是www.tonec.com,并且所有支持的协议都应用于此站点名称,如https://www.tonec.com和ftp://www.tonec.com。在此步骤中,您可以告诉Grabber仅查找当前站点上的所有文件,或者您可以指定要在当前(此)站点上处理的Web页面级别数以及要在其他站点上处理的Web页面级别数站点。单击以了解链接级别的数量。小心为其他站点设置大量级别,因为它可能会降低IDM显示无用文件的速度,并且可能导致处理数百万个不必要的页面。
如果选中“忽略弹出窗口”框,Grabber将不会浏览页面加载期间在浏览器中弹出的网页。请注意,弹出窗口术语不适用于Grabber,它适用于Web浏览器。除非您使用手动身份验证,否则抓取工具不会打开任何浏览器窗口。
如果起始网页具有相对于站点名称的路径(例如http://www.tonec.com/support/index.html),则“不浏览父目录”复选框将处于活动状态。如果选中“不浏览父目录”框,则Grabber将不会浏览相对于起始页面的父目录。例如,对于http://www.tonec.com/support/index.html,抓取工具不会浏览http://www.tonec.com/index.html和http://www.tonec.com/other /index.html,但将探索http://www.tonec.com/support/file.html和http://www.tonec.com/support/other/index.html
如果您选中“浏览主域中的所有站点”框,则Grabber将探索与起始页域具有共同部分的所有其他域。例如,对于http://www.tonec.com/support/index.html,抓取工具将探索http://tonec.com http://ftp.tonec.com和http://some.other.domain。 tonec.com。在子域上,Grabber将探索为当前站点指定的级别数。
抓取器还可以在页面上运行Java脚本并解析其结果。这样您就可以从站点检索更多链接,但您应该谨慎使用此功能。
如果单击“高级>>”按钮,对话框将展开并允许您为需要浏览页面的域/路径指定包含和排除过滤器您可以使用星号通配符匹配任意数量的任何字符以创建过滤模式。
步骤4.设置站点资源管理器筛选器。
在此步骤中,您应该为下载的文件设置文件类型,位置和其他过滤器。您可以为所有文件类型设置包含和排除过滤器。

如果您对预定义过滤器不满意,可以使用“添加过滤器”按钮添加/更改它们。单击“添加过滤器”后,将出现以下“编辑过滤器”对话框。

对于包含多种文件类型的过滤器,文件类型元素应使用逗号分隔,不带空格。星号通配符(*)表示任意数量的任何字符。使用通配符可以创建匹配多个文件名的模式,例如“image * .jpg”模式匹配从“image”单词开始的任何jpg图像文件名,如image01.jpg,image2.jpg,imageHot.jpg和image735.jpg 。可以在过滤器中使用“<start page>”表达式来指定第一步中设置的起始页。
如果选中“仅在此站点上搜索文件”框,则位于其他站点上的文件将不会显示在主Grabber窗口中,并且Grabber将不会检查这些文件的大小和类型。
在探索项目期间,Grabber很可能会在不同位置找到同一文件的许多副本。如果选中“隐藏在不同位置找到的重复文件”,则抓取器将仅显示找到的文件的第一个副本。如果文件具有相同的名称和相同的大小,则会将文件视为副本。启用“使用原始相对子文件夹”选项时,将禁用此选项。
如果选中“立即开始下载所有匹配的文件”,则会立即下载所有找到的文件。您可以先浏览该站点,检查所需的文件,然后在主Grabber窗口中下载它们,或将它们添加到IDM的主列表中。
“高级>>”按钮展开对话框,让您为Grabber将从中下载文件的路径/域设置包含和排除过滤器。您可以使用星号通配符(*)表示任意数量的任何字符。您还可以设置要下载的文件的最小和最大大小。